


Save more on cost. Pause now and restore right
where you left off later

Find Idle GPUs Across Multiple Clouds
Switch Providers Anytime Without Needing To Manage Multiple Cloud Accounts. Stay Flexible And Always Get The Best Deal.
Tools Like Data Backups, And More
Keep Your Data Safe And Systems Healthy With Backups, Monitoring, And Other Essential Cloud Tools.

All the power of top cloud providers; unified, simplified,
and optimized for AI.
Run powerful AI workloads in three simple steps.
Pick a GPU
STEP 01B200
(180GB)

H100
(80GB)
A100
(80GB)
Configure
STEP 02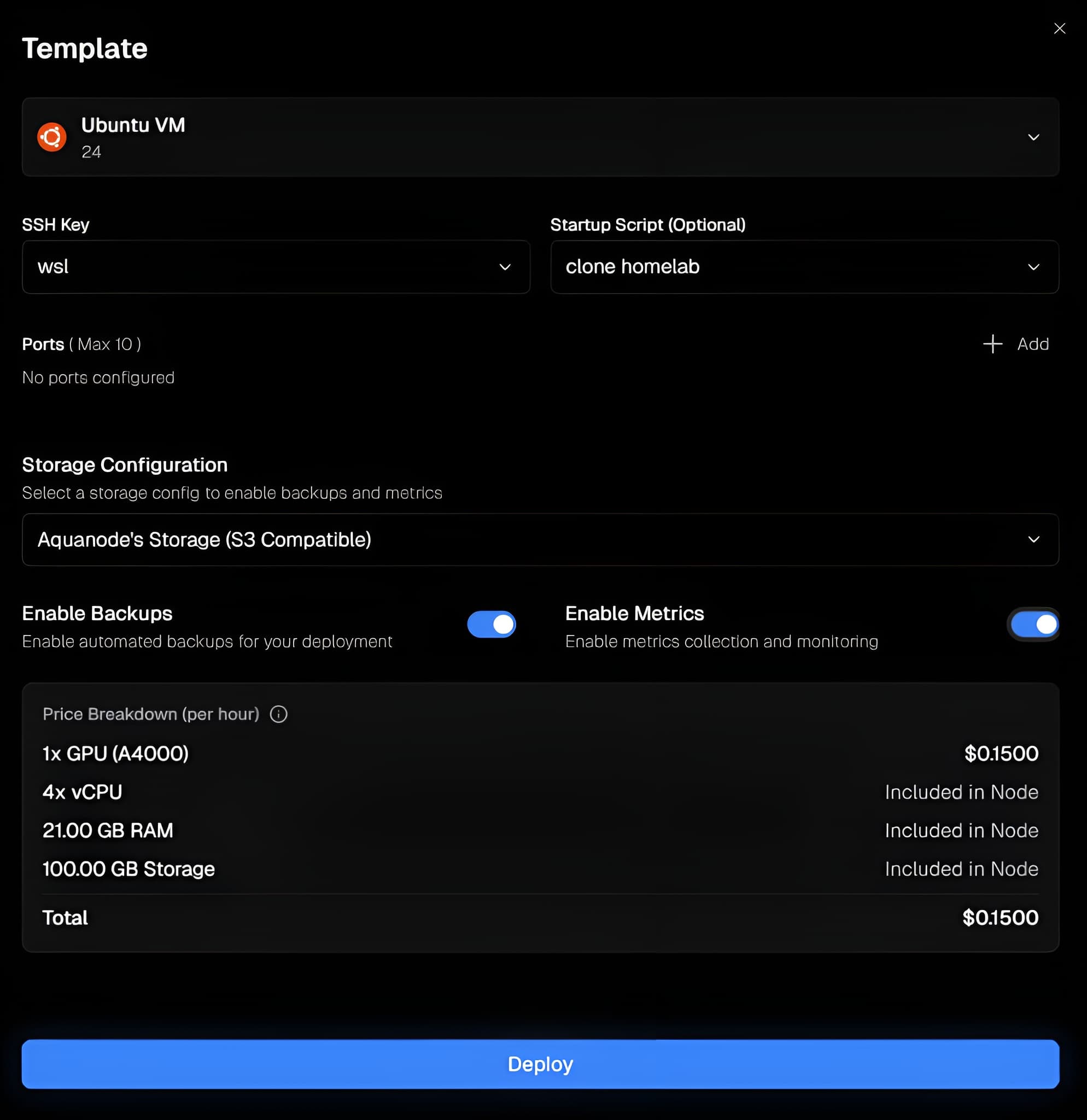
Deploy and Start Using
STEP 03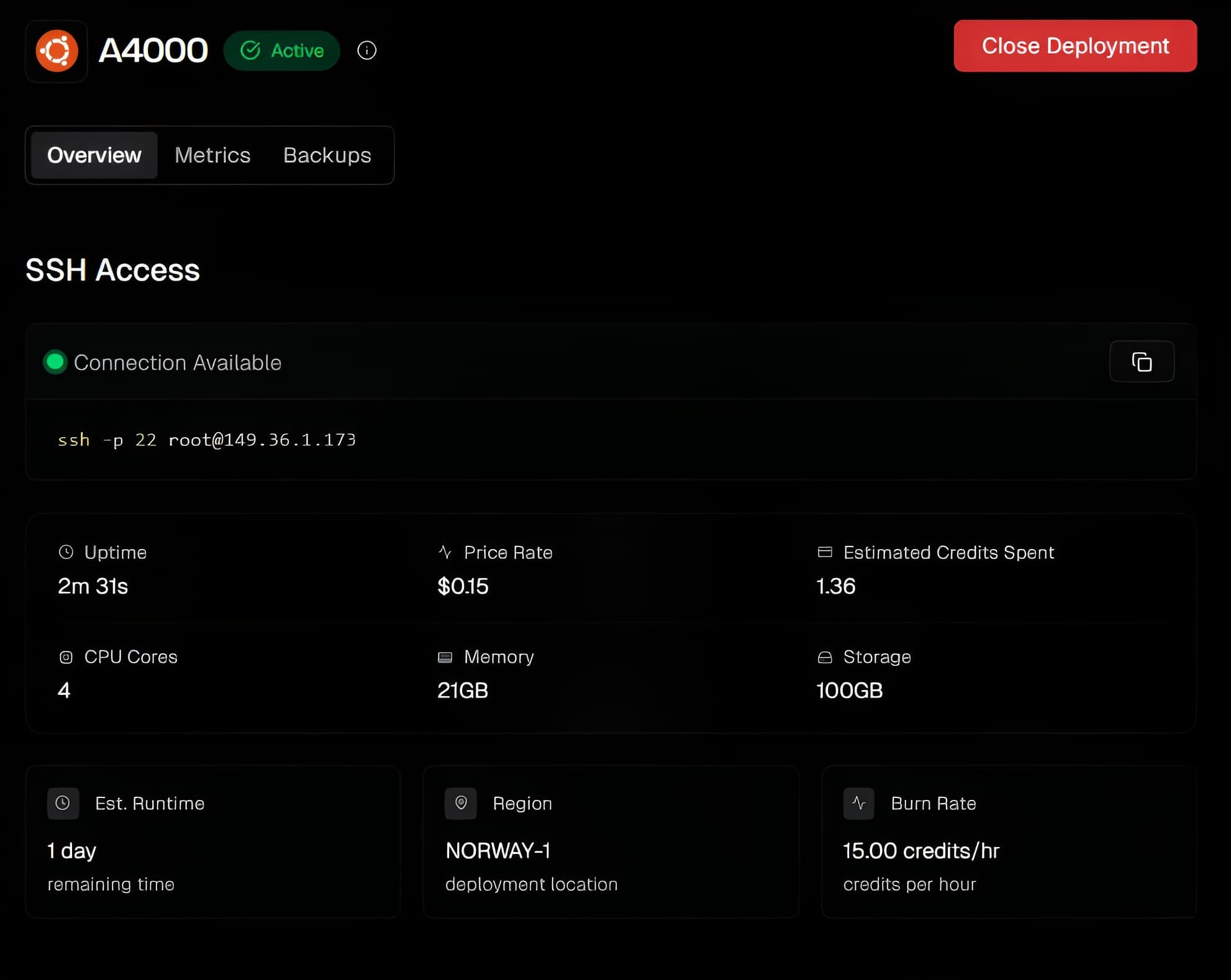
What you can do with
Aquanode

Train Large Language Models - Faster.
Accelerate your AI experiments with high-performance GPUs. Aquanode lets you train large models in less time, so you can iterate, test, and ship breakthroughs quicker.
Customize Existing Models
Easily adjust existing models with your own data to get results that match your project’s needs.
Run High-Performance Inference
Run your models efficiently to get accurate predictions in real time, making your applications more responsive.
AI Research & Experimentation
Experiment with new AI ideas and test different approaches without worrying about setting up or managing infrastructure.
Trusted by Builders Everywhere
Don't take our word for it, here's what builders like
you are saying.
I switched from Runpod to Aquanode, and it feels so much better to use. The GPUs are priced more reasonably! I'd highly recommend it.
ML Engineer
University of California, Los Angeles
The pause-and-resume feature makes it so much easier to manage our GPUs across multiple clouds.
Infrastructure Engineer
AI Startup
Core Features
GPU Pricing
One Account for
Multi-Cloud
No need to juggle multiple cloud accounts. Deploy everything from one place.
Centralized Billing
Across Cloud
Track and manage all your cloud costs from a single dashboard.
Multiple Ways to
Pay
Whether it’s crypto or traditional methods, we’ve got you covered.
Built-in Tools For
Every Cloud
Deploy Seamlessly with integrated connectors, and cross-cloud tools.
© 2025 Aquanode. All rights reserved.
All trademarks, logos and brand names are the
property of their respective owners.